Λογισμικό, λειτουργικά συστήματα, προγραμματισμός, hardware, δίκτυα, Internet
-
wooded glade
- Δημοσιεύσεις: 29284
- Εγγραφή: 02 Απρ 2018, 17:04
Μη αναγνωσμένη δημοσίευση
από wooded glade » 21 Μάιος 2021, 14:16
klg έγραψε: ↑21 Μάιος 2021, 14:04
nick έγραψε: ↑21 Μάιος 2021, 13:48
klg έγραψε: ↑21 Μάιος 2021, 13:32
Μαν ο wooded τρέχει vb6.
Νομιζω το εχουν σε πιο πολλές πλατφόρμες, μαλον οχι vb6.
Το προβλημα του Wooded ειναι οτι ο text parser επειστρεφει τις 4 παρακάτω λέξεις με τη σειρα που γράφτηκαν
οι εντολες του pdf διαβαζονται καπως ετσι
Κώδικας: Επιλογή όλων
print("top right", 0, 100)
print("top left", 0, 0)
print("bottom right", 100, 100)
print("bottom left", 100, 0)
Ο εξυπνος parser θα προσπαθήσει να τις επιστρέψει με τη σειρα που φαινονται στο χαρτι.
Κώδικας: Επιλογή όλων
top left top right
bottom left bottom right
Τα ξερω αυτα επειδη ειχα ασχοληθει με φορολογικούς μηχανισμούς ΕΑΔΦΣΣ και επρεπε να κάνουμε PDF ->text.
Βασικά υπάρχει το εξής ερώτημα σε σχέση με αυτό που κάνει ο wooded. Θέλει κάτι re-usable ή ένα one time hack; Αν θέλει κάτι re-usable πρέπει να απεικονίσει το περιεχόμενο του κειμένου σε μια μορφή που είναι παντελώς agnostic στο που εμφανίζεται τι αλλά να διατηρεί τις γραμματικές συνδέσεις του περιεχομένου. Εννοώ ότι αν το t-l, t-r,b-l, b-r που εκφράζει χωρικά κάτι, θα πρέπει να το κάνει encode σε ένα metasyntax notation, ώστε να μπορεί στο ενδιάμεσο AST να το έχει όπως πρέπει (i.e σαν γραμματική οντότητα), χωρίς να τον απασχολεί αν κάτι είναι 10 χαρακτήρες πιο δεξιά. Απλά θα διατρέξει το δέντρο και θα βρει τα tagged nodes που χρειάζεται.
Αν και νομίζω ότι δεν τον απασχολεί να κάνει κάτι τέτοιο.
Reusable βέβαια.
Ο Adobe το κάνει αλλά με λάθη που και που.
Το site που βρήκα κάνει όμως τέλειο text. Ο Nick που είπε ψάξε για parsers και όχι scrapers βοήθησε.
δεν είναι όλα κρού-σμα-τα
-
nick
- Δημοσιεύσεις: 5101
- Εγγραφή: 25 Μάιος 2018, 22:21
Μη αναγνωσμένη δημοσίευση
από nick » 21 Μάιος 2021, 14:17
Το πρόβλημα ειναι οτι το pdf μπορει να παρουσιασει κειμενο οριζοντια/καθετα/αναποδα με rotation μικρα/μεγαλα γραμματα και οτι φανταστεις.
Τι κειμενο περιμενεις να γραφτει στο notepad π.χ. απο αυτες τις εικονες
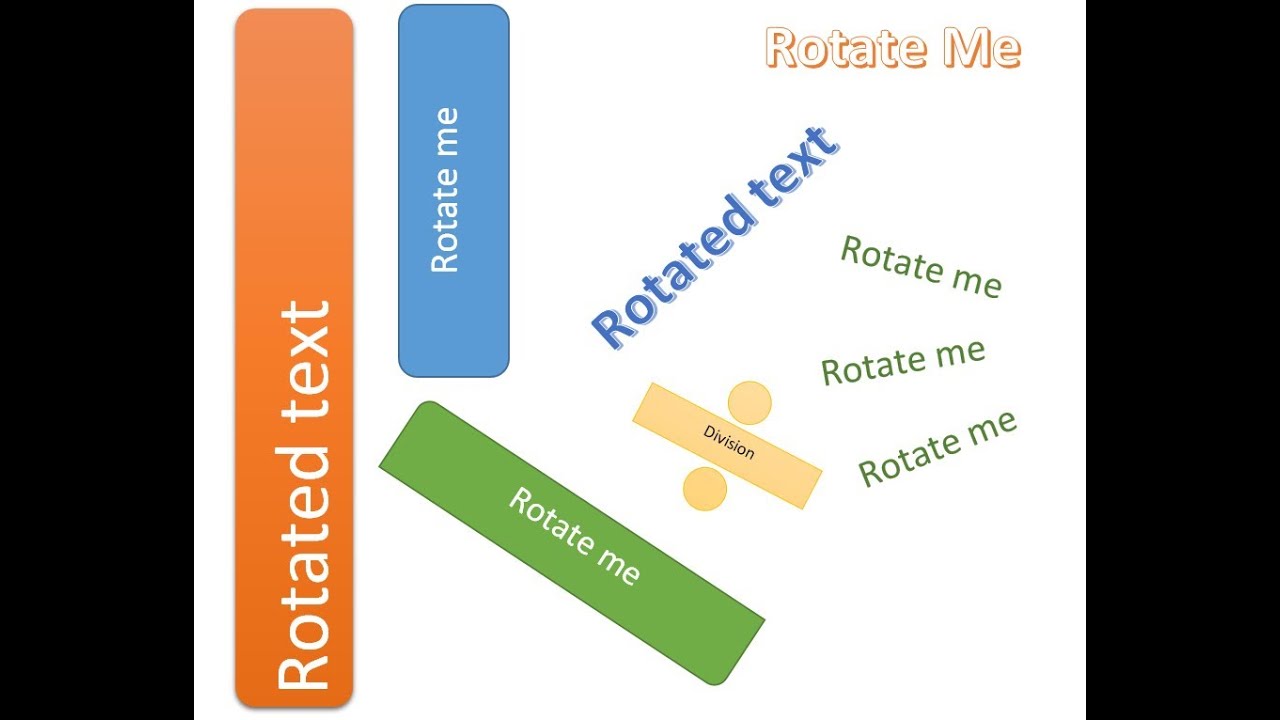

-
wooded glade
- Δημοσιεύσεις: 29284
- Εγγραφή: 02 Απρ 2018, 17:04
Μη αναγνωσμένη δημοσίευση
από wooded glade » 21 Μάιος 2021, 14:24
nick έγραψε: ↑21 Μάιος 2021, 14:17
Το πρόβλημα ειναι οτι το pdf μπορει να παρουσιασει κειμενο οριζοντια/καθετα/αναποδα με rotation μικρα/μεγαλα γραμματα και οτι φανταστεις.
Τι κειμενο περιμενεις να γραφτει στο notepad π.χ. απο αυτες τις εικονες
Καλά τα δικά μας δεν είναι τέτοια.
Υπάρχουν και σε text αλλού - χωρίς pdf - αλλά με λιγώτερα στοιχεία.
δεν είναι όλα κρού-σμα-τα
-
klg
- Δημοσιεύσεις: 3284
- Εγγραφή: 15 Οκτ 2018, 12:14
- Phorum.gr user: klg
Μη αναγνωσμένη δημοσίευση
από klg » 21 Μάιος 2021, 14:43
wooded glade έγραψε: ↑21 Μάιος 2021, 14:13
klg έγραψε: ↑21 Μάιος 2021, 14:06
wooded glade έγραψε: ↑21 Μάιος 2021, 13:56
Η VB μετά την 6.00 έχει ελλείψεις - planned obsolescense του Gates ο οποίος θέλει να μας βάλει και τα εμβόλια.
Στο έχουμε γράψει πολλές φορές ότι πρέπει να σταματήσεις να χρησιμοποιείς αυτή τη μαλακία και να αρχίσεις να γράφεις σε vb.net. Δεν υπάρχει καμία συνωμοσία του Gates, απλά είσαι μαλάκας (φιλικά στο γράφω, μην παρεξηγηθείς).
Αλλά έχει κάνει planned obsolescense ο τσιπάκιας τώρα, τι να λαίμαι. Εσύ έχεις πιαστεί κορόϊδο του τσιπάκια.
Εγώ δεν γράφω vb φίλε μου και από τον τσιπάκια έχω βγάλει πάρα πολλά λεφτά εδώ και χρόνια. Πάντως αυτό:
Ο Gates τη χάλασε εξεπίτηδες επειδή θέλει να μας βάλει εμβόλιο.
δεν το καταλαβαίνω.
Τι σχέση έχει η vb6 με το εμβόλιο; Αν δεν είχε κάνει planned obsolescence θα έγραφες ιό για να καταστρέψεις τα nanobots του εμβολίου σε vb6;
Ενπηρειά και σθένος σου πήρε 6 σελίδες να κάνεις άρνηση απαιτούμενος. Είμαι νεαρή γυναίκα, είμαι νεαρή γυναίκα, είμαι νεαρή γυναίκα, είμαι νεαρή γυναίκα. Ακόμα και οι Ζαίοι δεν χρειάζονται τα δύο χρώματα σαν κυρίες.
Thank you Google Translate.
-
wooded glade
- Δημοσιεύσεις: 29284
- Εγγραφή: 02 Απρ 2018, 17:04
Μη αναγνωσμένη δημοσίευση
από wooded glade » 10 Ιουν 2021, 06:59
Τελικά πήγα να διαβάσω pdf με αυτή τη μέθοδο του online αλλά δεν βγήκε καλό.
Οπτικά φαίνεται καλύτερο από του adobe αλλά όταν το είδα με προσοχή χάνει πολύ - γίνεται κάποιο randomization και δεν μπορείς να ορίσεις bookmarks για το διάβασμα (χειρότερο από adobe).
Λέει κάποιος ότι στα pdf παίζει ρόλο η σειρά που ακολουθεί αυτός που τα γράφει.
Δηλαδή αν η κανονική σειρά αυτών που θέλει να γράψει είναι "Α"-"Β"-"Γ" και αυτός το πάει με μιά σειρά "Γ"-"Β"-"Α", επηρεάζει το internal format of the document και το parsing.
Έχει κι άλλα online converter εκτός από το aspose που βρήκα αλλά δεν καταλαβαίνουν Ελληνικά τα περισσότερα.
Άλλο ;
Με OCR μπας και γίνεται ;
δεν είναι όλα κρού-σμα-τα
Phorum.com.gr : Αποποίηση Ευθυνών
Αποποίηση Ευθυνών Διαχείρισης Φόρουμ (Phorum.com.gr)
Οι απόψεις και τα σχόλια που δημοσιεύονται σε αυτό το Φόρουμ είναι προσωπικά και δεν αντιπροσωπεύουν αυτές της Διαχείρισης του Phorum.com.gr
Το κάθε μέλος, σύμφωνα με τους όρους χρήσης που αποδέχτηκε κατά την εγγραφή του, φέρει την αποκλειστική ευθύνη των δημοσιεύσεών του, των απόψεων / θέσεων που εκφράζονται
μέσω αυτής, καθώς και την επιλογή συνδέσμων που τυχόν συμπεριλαμβάνονται.
Η Διαχείριση του Phorum.com.gr σε καμία περίπτωση δεν αποδέχεται οποιαδήποτε ευθύνη, για οποιαδήποτε συμβουλή ή συστάσεις που κάνει ή υπονοεί κάποιο μέλος ή επισκέπτης του Phorum.com.gr
η οποία έχει ως αποτέλεσμα οποιαδήποτε απώλεια / ζημία, με οποιονδήποτε τρόπο, για μέλος του Phorum.com.gr, ή για οποιοδήποτε άλλο πρόσωπο.
Επιπλέον, η Διαχείριση του Phorum.com.gr δεν είναι και δεν μπορεί να είναι υπεύθυνη, για το περιεχόμενο οποιουδήποτε άλλου ιστοτόπου στο Διαδίκτυο,
που έχει συνδεθεί με σύνδεσμο (link) από το Phorum.com.gr
Για άμεση επικοινωνία με τη Διαχείριση του Phorum.com.gr μπορείτε να συμπληρώνετε τη φόρμα της σελίδας Επικοινωνίας του Phorum.com.gr παρακάτω.

